





Мы тоже много лет назад начинали писать код и обслуживать проекты по простой схеме:
- подключаемся к серверу
- открываем нужный файл
- пишем код
- сохраняем изменения
В принципе этого достаточно и если вы в одиночку работаете над небольшим проектом, внедрение сложных схем - неоправданный шаг.
Как водится, до всего нужно дорасти. И если вы начинаете работать командой, использовать несколько площадок для развертывания и работать с большой кодовой базой, то вас как пробку от шампанского вытолкнет к переменам. В противном случае сначала вы столкнетесь с дежурными проблемами: затерли код коллеги, потеряли изменения, допустили ошибку и теперь нужно ночь сидеть искать причину, ну а далее в какой-то момент вы поймете, что просто не можете обеспечивать поддержку и развитие проекта, т.к. энтропия достигла критических значений.
А если проектов много? А если коллег много? Как навести порядок и сделать производственный процесс прозрачным? - Правильно, контроль версий.
На выбор есть несколько популярных инструментов: git, Mercurial и дедушка SVN.
Первый - безусловный лидер, вокруг него сформировано самое большое сообщество и, как следствие, самая развитая инфраструктура: GitHub, GitLab и интеграция, наверное, во всех современных инструментах и средах. Его используем мы и рассказывать будем о нём.
Что представляет из себя git?
Это распределенный реестр с набором инструментов.
Сейчас на слуху технология blockchain, так вот git в некотором роде и есть blockchain. Все транзакции учтены, система распределена и децентрализована, подмена транзакций исключена, всё контролируют хэши.
Проект под управлением git представляет из себя дерево, математический граф, от чего многие сущности в нем называются соответствующим образом: tree, branch

Каждая ветка - это копия состояния другой ветки на момент создания. Первоначально есть только ветка master и ветвление начинается с нее. Ветки могут сколь угодно ветвиться друг от друга и сливаться вместе. Важно понимать, что они фиксируют именно состояние файлов и изменения в них, а не копии самих файлов. Поэтому хоть репозиторий со временем и растет в размерах, но незначительно.
Единицей информации в git считается коммит (commit). Это пакет изменений, становящейся транзакцией. Если что-то попало в коммит, эти данные уже никогда не потеряются в проекте, их всегда можно будет восстановить, поэтому коммиты лучше не экономить и делать почаще, снабжая емкими комментариями, так вы сами себе облегчите работу с проектом в дальнейшем.
Как начать?
Начать очень просто, особенно если вы работает под Linux (в нашем случае Ubuntu).
В этом случае открываем терминал и просим систему установить из репозитория текущую стабильную версию git:

Для других систем перейдите в раздел загрузки на оф.сайте и проведите стандартную процедуру установки.
Теперь перейдем в директорию нашего проекта и инициируем новый репозиторий:
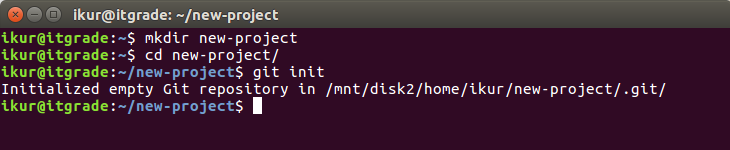
Всё, теперь всё содержимое этого раздела и все будущие изменения в нём будут отслеживаться контролем версий.
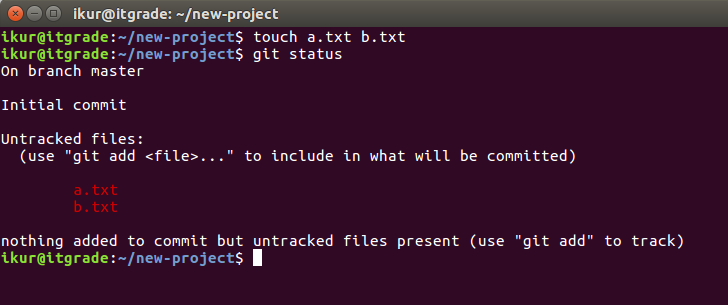
Мониторить текущую ситуацию с изменениями можно с помощью команды git status.
Создадим два новых файла и проверим видит ли система контроля изменения в рабочей директории:
Добавим файлы к коммиту командой git add:
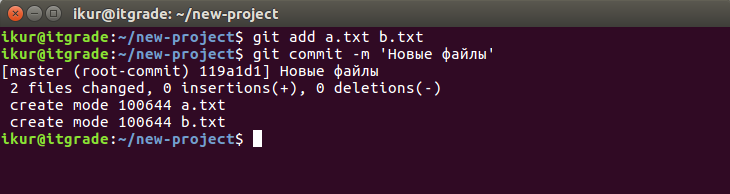
Наш коммит получил идентификатор 119a1d1, это сокращенный вариант длинного хэша, по которому система контроля хранит транзакции и обращается к ним.
Проверим историю коммитов командой git log:
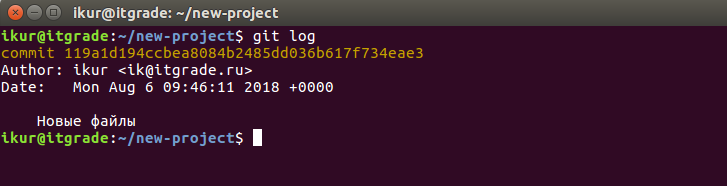
Как видим, наш коммит прописался в реестр.
Теперь удалим один из файлов и запишем это в новый коммит:
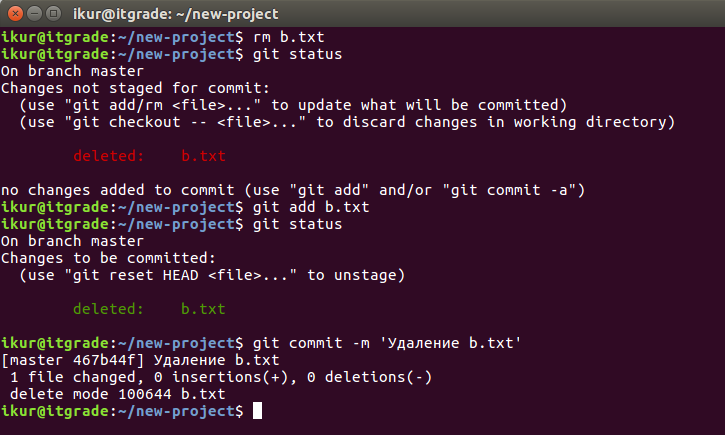
Файла b.txt больше нет физически в проекте, но для системы контроля он навсегда сохранен в одном из коммитов.
Предположим b.txt нам снова понадобился.
Проверим историю коммитов и возвратим состояние ветки на нужный нам коммит, где этот файл присутствует:
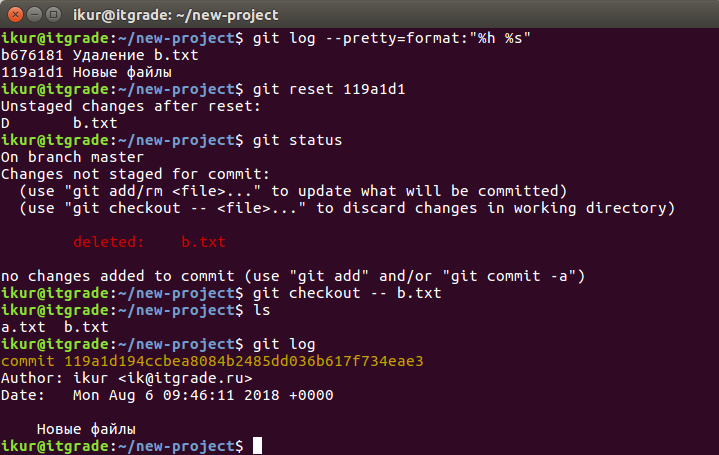
Мы воспользовались более сложным вариантом git log для вывода емкой истории коммитов, командой git reset переключили состояние ветки, командой git status проверили состояние файлов на момент перед коммитом, с помощью git checkout из подсказки отменили внесенные изменения и системной командой ls убедились в том, что файл b.txt снова на месте.
Теперь создадим ветку, в которой будем вести параллельную разработку:
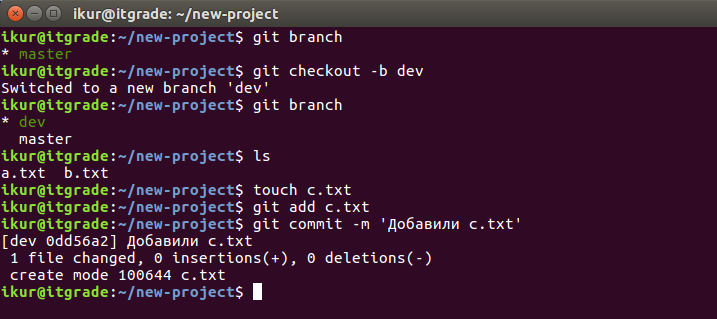
Мы проверили текущую ветку с помощью git branch, переключились на новую ветку с помощью git checkout, создали и закоммитили новый файл.
Переключимся обратно на master и убедимся, что никакого c.txt здесь нет.

Сведем обе ветки:
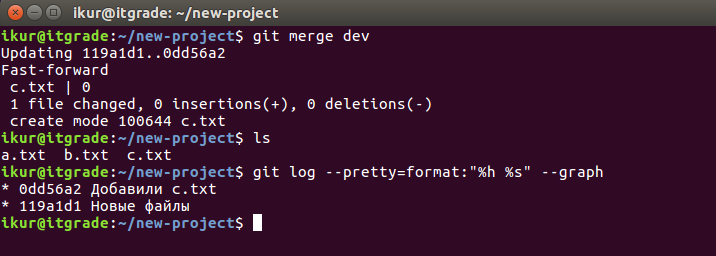
Как видим, c.txt и соответствующий коммит появились в ветке master.
Сценариев использования контроля версий великое множество, мы постараемся раскрыть их в следующих публикациях.
Что дальше?
- Обучаете сотрудников навыкам работы с git
- Подключаете собственный репозиторий проектов (GitHub, GitLab, BitBucket или собственный)
- Формируете команды по рангам - тимлиды, джуниоры, сеньоры, тестировщики, devops'ы
- Настраиваете среды развертывания
- Интегрируете контроль версий с IDE
- Налаживаете производственные линии
Что мы получили, внедрив контроль версий?
- Рабочий процесс стал осязаемым и прозрачным
- Все изменения фиксируются, результат труда не теряется
- Возможность подключать к разработке множество сотрудников
- Прозрачность действий участников разработки
- Возможность быстро откатывать проект на нужное состояние
- Возможность вести параллельные наработки и выкатывать их на проект по мере готовности, не тормозя другие наработки
- Возможность работать со множеством проектов и масштабироваться
- Проведение code-review и предрелизного тестирования, допуская на продакшн только надежные и проверенные изменения
- Настроили автоматические схемы развертывания изменений
- Построили более эффективные производственные схемы



















